GBDT-MO: Gradient Boosted Decision Trees for Multiple Outputs
Zhendong Zhang and Cheolkon Jung
Xidian University
Abstract
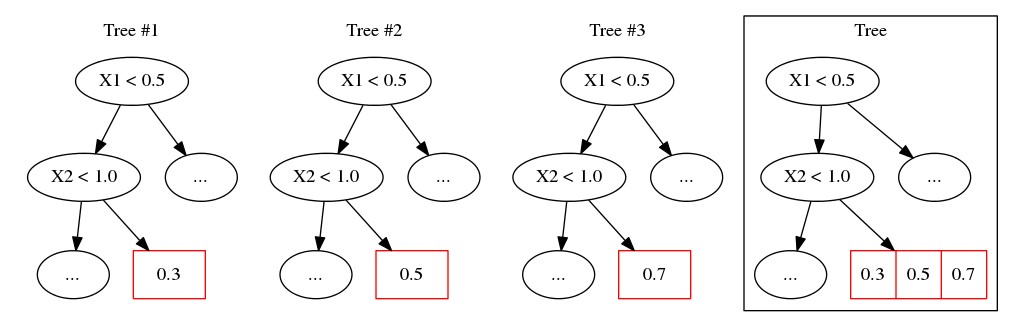
Gradient boosted decision trees (GBDTs) are widely used in machine learning, and the output of current GBDT implementations is a single variable. When there are multiple outputs, GBDT constructs multiple trees corresponding to the output variables. The correlations between variables are ignored by such a strategy causing redundancy of the learned tree structures. In this paper, we propose a general method to learn GBDT for multiple outputs, called GBDT-MO. Each leaf of GBDT-MO constructs predictions of all variables or a subset of automatically selected variables. This is achieved by considering the summation of objective gains over all output variables. Moreover, we extend histogram approximation into multiple output case to speed up the training process. Various experiments on synthetic and real-world datasets verify that GBDT-MO achieves outstanding performance in terms of both accuracy and training speed.
Codes
https://github.com/zzd1992/GBDTMO
For reference, we implemented GBDT-MO from scratch by C++. We provide a Python interface along with codes. Our implementations are similar to LightGBM except for the learning mechanisms designed for multiple outputs. Some advanced features are not included, such as GPU training and distributed training.
Paper
Citation:
@article{zhang2020GBDT-MO,
title={GBDT-MO: Gradient Boosted Decision Trees for Multiple Outputs},
author={Zhang, Zhendong and Jung, Cheolkon},
journal={IEEE Transactions on Neural Networks and Learning Systems},
year={2020},
publisher={IEEE}
}
Zhendong Zhang and Cheolkon Jung, “GBDT-MO: Gradient Boosted Decision Trees for Multiple Outputs,” IEEE Transactions on Neural Networks and Learning Systems, 2020
Results:
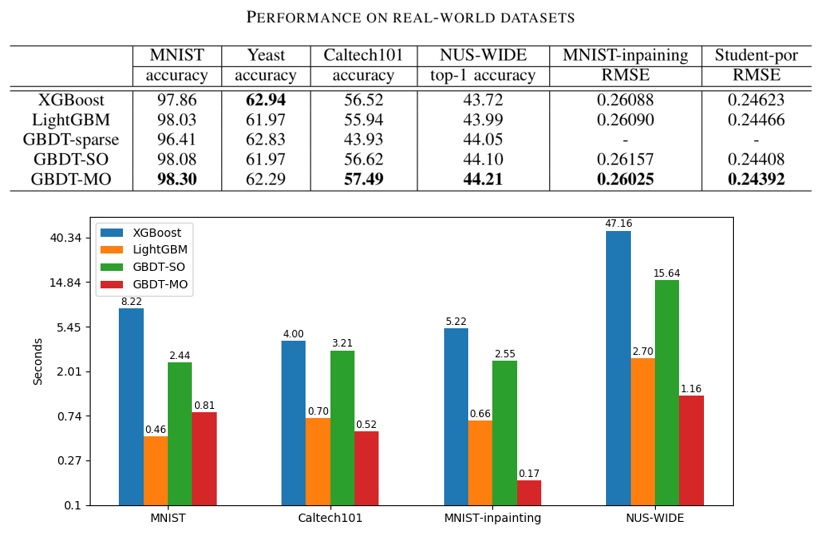
We show test performance on six real-world datasets. We also show training speed in log scale. Here, GBDT-SO is our own implementation of GBDT for single output. GBDT-MO achieves better performance and faster training speed than GBDT-SO.
Acknowledgement
This work was supported by the National Natural Science Foundation of China (No. 61271298) and the International S&T Cooperation Program of China (No. 2014DFG12780).