Siamese Dense Network for Reflection Removal with Flash and No-Flash Image Pairs
Yakun Chang, Cheolkon Jung, Jun Sun and Fengqiao Wang
Xidian University
Abstract
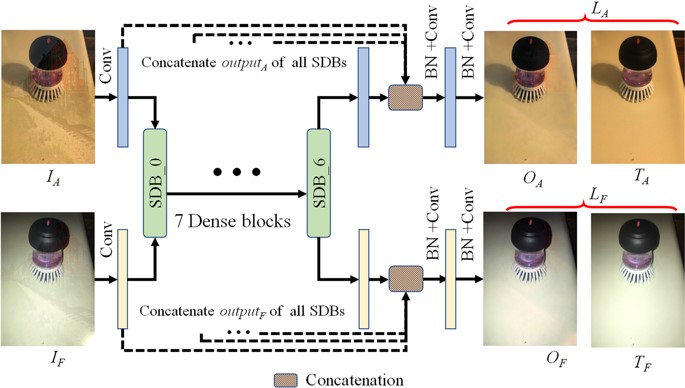
This work addresses the reflection removal with flash and no-flash image pairs to separate reflection from transmission. When objects are covered by glass, the no-flash image usually contains reflection, and thus flash is used to enhance transmission details. However, the flash image suffers from the specular highlight on the glass surface caused by flash. In this paper, we propose a siamese dense network (SDN) for reflection removal with flash and no-flash image pairs. SDN extracts shareable and complementary features via concatenated siamese dense blocks. We utilize an image fusion block for the SDN to fuse the intermediate output of two branches. Since severe information loss occurs in the specular highlight, we detect the specular highlight in the flash image based on gradient of the maximum chromaticity. Through observations, flash causes various artifacts such as tone distortion and inhomogeneous brightness. Thus, with synthetic datasets we collect 758 pairs of real flash and no-flash image pairs (including their ground truth) by different cameras to gain generalization. Various experiments show that the proposed method successfully removes reflections using flash and no-flash image pairs and outperforms state-of-the-art ones in terms of visual quality and quantitative measurements. Besides, we apply the SDN to color/depth image pairs and achieve both color reflection removal and depth filling.
Codes and Datasets:
https://github.com/YKChang92/SDN
Paper
Citation:
@article{chang2020siamese,
title={Siamese Dense Network for Reflection Removal with Flash and No-Flash Image Pairs},
author={Chang, Yakun and Jung, Cheolkon and Sun, Jun and Wang, Fengqiao},
journal={International Journal of Computer Vision},
volume={128},
pages={1673--1698},
year={2020},
publisher={Springer}
}
Yakun Chang, Cheolkon Jung, Jun Sun, and Fengqiao Wang, "Siamese Dense Network for Reflection Removal with Flash and No-Flash Image Pairs," International Journal of Computer Vision, vol. 128, pp. 1673-1698, 2020.
Results:

Left to right: Input no-flash image, output OA, input flash image, output OF , our final output Of and ground truth.
Acknowledgement
This work was supported by the National Natural Science Foundation of China (No. 61271298) and the International S&T Cooperation Program of China (No. 2014DFG12780).